
| słowa kluczowe: historia, nauka. | |||
| Historia | 2013.01.21 23:37 | ||
Matematyka pomaga lepiej zrozumieć historię | Hanys | ||
|
Tytus Liwiusz (59 p.n.e. - 17 n.e.) jest autorem monumentalnego dzieła „Od założenia Miasta” (Ab Urbe condita libri CXLII). Jego dzieło, zawierające pierwotnie 142 woluminy, pozostaje do dziś jednym z najważniejszych źródeł poznania historii starożytnego Rzymu. | |||
| Zapewne tylko nieliczni wiedzą, że matematykę można z powodzeniem zastosować do datowania i analizy chronologii wydarzeń historycznych, opisanych w starych kronikach. Trudno w to uwierzyć, ale już od kilkudziesięciu lat istnieją metody matematyczno-statystyczne, które pozwalają to zrobić. Zostały one opracowane i wdrożone przez zespół rosyjskich matematyków (Kałasznikow, Fomenko, Nosowski, Raczew, Fedorow). Zaliczamy do nich takie specjalistyczne narzędzia, jak metodę rozpoznawania i datowania dynastii władców (tj. model małych zniekształceń dynastycznych), metodę porządkowania tekstów historycznych w czasie, model tłumienia częstotliwości, model dublowania częstotliwości (tj. wychwytywania duplikatów), metodę datowania wydarzeń, metodę ankiet-kodów (porównanie potoków biograficznych) i metodę korelacji lokalnych maksimów. Ostatnią z nich postaram się opisać niżej.
METODA KORELACJI AMPLITUD LOKALNYCH MAKSIMÓW (FUNKCJA POJEMNOŚCI TEKSTU HISTORYCZNEGO, KRONIKI ZALEŻNE I NIEZALEŻNE)
Różnorodne charakterystyki pojemności informacji można tworzyć przez dokładne podliczenie: Każda charakterystyka przypisuje do każdego opisanego w kronice roku t konkretną liczbę, a więc różnym latom będą odpowiadać różne liczby. Mówiąc ogólnie, poszczególne pojemności rozdziałów X(t) będą zmieniać się wraz ze zmianą numeracji (roku) t. Sekwencję pojemności X(A),…,X(B) nazwijmy funkcją pojemności danego tekstu X.
Jak widać na rys.1, istotną cechą pojemności vol X(t) są lata t, w czasie których krzywa wykresu osiąga szczyt, tj. lokalne maksimum. Oznacza to, że rok, na który przypada taki szczyt (inaczej niż w innych latach, dla których wykres nie odnotowuje pików, tj. skoków przebiegu krzywej), musiał być przez kronikarza opisany bardziej szczegółowo, na przykład na większej ilości stron. Zresztą w różnych kronikach X i Y „szczegółowo opisanymi” mogą okazać się zupełnie różne lata. Może to być spowodowane tym, że kronikarz miał do wglądu większą ilość zachowanych do jego czasów materiałów źródłowych i informacji dotyczących danego roku albo z jakichś innych przyczyn (koniunkturalnych, propagandowych itp.) poświęcił opisowi danego roku znacznie więcej uwagi niż innym latom. Kroniki historyczne X i Y, w przypadku których wierzchołki wykresów pokrywają się, można nazwać ZALEŻNYMI (patrz rys.1). Oznacza to, że opierają się one na tym samym pierwotnym źródle historycznym i opisują praktycznie te same wydarzenia w identycznym przedziale czasowym (A,B) z historii tego samego regionu geograficznego. Natomiast kroniki, które opisują wydarzenia z całkiem różnych przedziałów czasowych bądź różnych regionów geograficznych, nazwiemy NIEZALEŻNYMI. Zależność bądź niezależność kronik można ustalić porównując ich funkcje pojemności. Innymi słowy: punkty lokalnych maksimów na wykresach pojemności kronik zależnych będą ze sobą „korelować”, zaś w przypadku kronik niezależnych taka „korelacja” w ogóle nie będzie występowała. Przykład braku korelacji ilustruje poniższy wykres: Metody identyfikacji kronik zależnych i niezależnych okazały się dostatecznie efektywne przy porównywaniu kronik o mniej więcej jednakowej pojemności, lecz w przypadku kronik o zdecydowanie różnej pojemności sytuacja zaczyna się komplikować. Model korelacji lokalnych maksimów oparty jest na konkluzji, że różni kronikarze opisujący tę samą epokę historyczną posługiwali się zasadniczo tą samą pojemnością, tj. zbiorem ocalałej do ich czasów informacji. Jak wykazały eksperymenty, te lata, dla których zachowało się dużo tekstów, opisywali bardzo szczegółowo, a pozostałe lata - mniej szczegółowo. Z biegiem czasu teksty pierwotne, napisane przez współczesnych - naocznych świadków wydarzeń - roku t, stopniowo ulegają zapomnieniu i utraceniu. Krzywa C(t) przedstawia obraz pierwotnego zbioru informacji, a krzywa C_M(t) to wykres późniejszego zbioru informacji, z których wiele zostało już utracone. Niech C(t) będzie pojemnością wszystkich dokumentów, napisanych przez ludzi żyjących w roku t, relacjonujących wydarzenia tego roku.
Niech X i Y oznacza kronikarzy, pragnących napisać historię epoki (A,B), którzy nie są naocznymi świadkami wydarzeń tejże epoki, gdyż żyli w czasach późniejszych. Niech M (lub odpowiednio N) będzie rokiem, w którym kronikarz X (lub odpowiednio Y) opublikował kronikę epoki (A,B). C_M(t) to pojemność dokumentów, które ocalały z epoki (A,B) do chwili M, to znaczy do epoki, w której żył kronikarz X. Inaczej mówiąc, są to ostatki pierwotnych tekstów, zachowanych do czasu M. Wykres graficzny C_M(t) jest więc wykresem pojemności ocalałej informacji o wydarzeniach epoki (A,B). Analogicznie sprawa przedstawia się z wykresem C_N(t). Sedno modelu korelacji maksimów sprowadza się tutaj do spostrzeżenia, że każdy kronikarz X opisujący epokę (A,B) z reguły bardziej szczegółowo opisuje te lata, dla których wykres C_M(t) charakteryzuje się skokami przebiegu krzywej , tzn. im więcej dokumentów z epoki (A,B) doszło do kronikarza X, tym dokładniej i bardziej szczegółowo opisuje on ten czas:
"Ubogie" i "bogate" kroniki i zakresy kronik: różnice między ubogimi a bogatymi kronikami można intuicyjnie rozpoznać na następującym wykresie:
Ubogimi kronikami są takie kroniki, w których „większość” zakresów pojemności vol X(t) jest zerowa, tzn. większości lat kronikarz w ogóle nie opisał. Bogatą kroniką natomiast nazwiemy taką kronikę, w której przeciwnie „większość” zakresów pojemności vol X(t) jest różna od zera, czyli kronikarz przekazuje dużo wiadomości o wydarzeniach z epoki (A,B). Oczywiście w realnych warunkach trudno jest jednoznacznie zakwalifikować tę czy inną kronikę do ubogich lub bogatych. Z tego powodu wprowadzono pojęcia ubogich i bogatych stref w kronice, co zostało zilustrowane na rys.6:
Oczywiście zdarzają się też sytuacje, w których biedna strefa może być usytuowana „w środku”:
Istotne i nieistotne zera funkcji pojemności. Przy analizowaniu konkretnej kroniki zamiast skrajnego lewego punktu A na osi czasu, za punkt wyjścia bierzemy pierwszy rok, dla którego vol X(A) jest różny od zera, co znaczy, że rok ten został opisany przez kronikarza. Zero wykresu pojemności nazwiemy istotnym wtedy, gdy jest ono usytuowane na prawo od pierwszej niezerowej wartości wykresu. Patrz rys.8:
Model amplitudowej korelacji wykresów pojemności w ubogich strefach kronik. Wyciągnijmy wnioski z modelu poszanowania informacji: Załóżmy, że dwóch kronikarzy X i Y opisuje te same wydarzenia, dziejące się w tym samym przedziale czasu (A,B). Każdy z nich dostatecznie dobrze kopiuje wykres pojemności ubogich stref zasobu ocalonych informacji o zdarzeniach epoki (A,B). W konsekwencji wykresy pojemności kroniki X i pojemności kroniki Y będą podobne w obrębie ubogich stref. Wywiedziona z tego prawidłowość statystyczna nosi nazwę modelu amplitudowej korelacji w ubogich strefach. Podsumujmy: Opis modelu statystycznego i formalizacja. Rozpatrzmy przedział czasu (A,B) i wprowadźmy do niego współrzędną x, zmieniającą się od 0 do B-A, gdzie B-A to długość interesującego nas odcinka czasu. Zrozumiałe, że x=t-A. Niech f(x)=vol X(x) będzie funkcją pojemności kroniki X. Jako G(x) oznaczmy funkcję G(x)=f(0)+f(1)+...+f(x), to znaczy „przedział” funkcji f od 0 do x. Nazwijmy tę funkcję skumulowaną sumą kroniki X. Rozpatrzmy standaryzowaną skumulowaną sumę F(x) = G(x)/vol X, gdzie vol X to całkowita pojemność kroniki. Standaryzowana skumulowana suma jest wyrażona wykresem niemalejącym, którego wartości rosną od 0 do 1. Dla różnych kronik charakter tego wzrostu będzie różny. Rozpatrzmy nową funkcję g(x)=1-F(x), patrz rys.10:
Jak widać z wykresu, wartości tej funkcji nie rosną. Nie wdając się zanadto w szczegóły, sformułujmy następujący model: funkcja g(x)=1-F(x) powinna zachowywać się w ubogiej, początkowej strefie kroniki jak funkcja exp(-(lambda) x^(alfa) ). W statystyce matematycznej tego rodzaju rozkłady nazywamy rozkładami Weibulla-Gnedenko. Jak widać, dysponujemy dwoma stopniami swobody: parametrem lambda i parametrem alfa, zmieniając które spróbujemy aproksymować funkcję 1-F(x). Jeśli uda się to zrobić dla konkretnych kronik, będzie to równoznaczne z potwierdzeniem modelu teoretycznego. Przeprowadzone na realnych kronikach eksperymenty statystyczne faktycznie wykazały, iż tłumienie wykresu 1-F(x) dostatecznie dobrze aproksymuje funkcję exp(-(lambda) x^(alpha) ) przy odpowiednim doborze wartości lambda i alfa. W rezultacie każdej kronice, a dokładniej mówiąc, początkowej ubogiej strefie kroniki możemy przyporządkować dwie liczby, wyrażające charakter zachowania funkcji pojemności kroniki. Nazwijmy lambda parametrem pojemności kroniki, a alfa parametrem formy kroniki. Najważniejszy dla nas jest parametr alfa. Jak wykazały eksperymenty statystyczne, to właśnie on najlepiej czuje charakter rozkładu oddzielnych, rzadkich pików wykresu pojemności w obrębie ubogiej strefy kroniki. To przede wszystkim parametr alfa będzie wskazywał, czy kroniki są zależne czy niezależne, natomiast parametr lambda jest bardziej odpowiedzialny za pojemność kroniki i wyczuwa, w jakim stopniu kronika jest uboga lub bogata. Powyższą hipotezę, model statystyczny, można przeformułować w następujący sposób: Wygodnie jest przedstawiać parę liczb (alfa, lambda) jako punkt na zwykłej płaszczyźnie w układzie współrzędnych kartezjańskich alfa i lambda, patrz rys.11:
Wzrost parametru "formy" kroniki wraz z upływem czasu. Przejdźmy do bardziej dokładnego opisu modelu statystycznego i oceńmy, w jakim stopniu dwa wykresy jednocześnie robią skoki - narzędzia statystystyczne pozwalają nam określić parametr p(X,Y), mierzący rozbieżność lat szczegółowo opisanych w kronice X i lat szczegółowo opisanych w kronice Y. Traktując obserwowaną bliskość pików (skoków krzywej) na obu wykresach jako zdarzenie losowe, można liczbę p(X,Y) rozpatrywać jako prawdopodobieństwo tego zdarzenia. Im liczba ta jest mniejsza, tym lata szczegółowo opisane w X lepiej pokrywają się z latami szczegółowo opisanymi w Y. Do celów matematycznej definicji parametru p(X,Y) weźmy przedział czasu (A,B) i wykres pojemności vol X(t), który osiąga lokalne maksima w określonych punktach m_1,...,m_n-1. Dla większego uproszczenia można przyjąć, że każde lokalne maksimum jest odwzorowane równo w jednym punkcie. Te punkty, czyli lata m_i, dzielą przedział (A,B) na określone odcinki różnej długości. Patrz rys.12:
Mierząc długości otrzymanych odcinków w latach, tj. mierząc odległości między punktami sąsiednich lokalnych maksimów m_i i m_i+1 otrzymamy sekwencję liczb całkowitych a(X)=(x_1,...,x_n). Liczba x_1 oznacza tutaj odległość między punktem A i pierwszym lokalnym maksimum, liczba x_2 oznacza odległość między pierwszym i drugim lokalnym maksimum. Liczba x_n to odległość między ostatnim lokalnym maksimum m_n-1 i punktem B. Tą sekwencję można opisać wektorem a(X) w przestrzeni euklidesowej R^n wymiaru n. I tak przykładowo przy zaistnieniu dwóch lokalnych maksimów, tzn. wtedy, gdy n=3, otrzymamy wektor całkowitoliczbowy a(X)=(x_1,x_2,x_3) w trójwymiarowej przestrzeni. Nazwijmy wektor a(X)=(x_1,x_2,x_3) wektorem lokalnych maksimów kroniki X. Dla drugiej kroniki Y będziemy mieli inny wektor a(Y)=(y_1,...,y_m). Przyjmujemy, że kronika Y opisuje wydarzenia w przedziale czasu (C,D), którego długość jest równa długości (A,B), tzn. B-A=D-C. By porównać wykresy pojemności kronik X i Y połączmy dwa odcinki czasowe (A,B) i (C,D) o jednakowej długości, nakładając je na siebie. Bez uszczerbku dla całości można uznać, że liczba maksimów jest jednakowa i dlatego wektory a(X) i a(Y) dwóch porównywanych kronik X i Y posiadają jednakową liczbę współrzędnych. Jeśli jednak liczba maksimów dwóch porównywanych wykresów byłaby różna, to można przyjąć, że niektóre maksima są krotne, tzn. w jednym punkcie zostało skomasowanych kilka lokalnych maksimów. Zarazem długości odpowiednich odcinków, które odpowiadają maksimom krotnym , można uznać za równe zeru. Wprawdzie wariant wprowadzenia maksimów krotnych jest niejednoznaczny, jednak dzięki niemu wstępnie można wyrównywać liczbę lokalnych maksimów na wykresach pojemności kronik X i Y. W dalszym postępowaniu można oczywiście pozbyć się tej niejednoznaczności, minimalizując niezbędne współczynniki bliskości wszelkimi możliwymi sposobami wprowadzenia maksimów krotnych. Warto zauważyć, że wprowadzenie maksimów krotnych oznacza, że w wektorze a(X) w niektórych miejscach pojawią się zerowe komponenty, czyli odcinki o zerowej długości. Tak więc porównując kroniki X i Y można uznać, że oba wektory a(X)=(x_1,...,x_n) i a(Y)=(y_1,...,y_n) mają tę samą liczbę współrzędnych i dlatego zawierają się w tej samej przestrzeni euklidesowej R^n. Zauważmy, że u każdego z tych wektorów suma jego współrzędnych jest jednakowa i równa się B-A=D-C, tj. długości przedziału czasu (A,B). Tak więc: x_1 + ... + x_n = y_1 + ... + y_n = B-A.
Ustalmy teraz wektor a(X)=(x_1,...,x_n) i rozpatrzmy wszystkie wektory c=(c_1,...,c_n) z rzeczywistymi współrzędnymi, należące do sympleksu L i spełniające jeszcze jeden dodatkowy warunek: Zbiór wszystkich takich wektorów c=(c_1,...,c_n) oznaczamy mianem K. Matematycznie można te wektory opisać jako oddalone od ustalonego wektora a(X) na odległość nie przekraczającą odległości r(X,Y) między wektorem a(X) i wektorem a(Y). Mówiąc o odległości między wektorami, mamy na myśli odległość między ich końcami. Zwróćmy uwagę, że wielkość (y_1 - x_1)^2 + ... + (y_n - x_n)^2 jest równa kwadratowi odległości r(X,Y) między wektorami a(X) i a(Y). Dlatego więc zbiór K to część sympleksu L, wchodzacy w "n-wymiarową" kulę o promieniu r(X,Y) ze środkiem w punkcie a(X). liczba "całych punktów" w zbiorze K Zwróćmy szczególną uwagę na interpretację parametru liczbowego p'(X,Y). Jeśli założymy, że wektor c=(c_1,...,c_n) zupełnie przypadkowo „przebiega” wszystkie wektory ze zbioru S, a przy tym z jednakowym prawdopodobieństwem może znaleźć się w dowolnym punkcie tego zbioru, to mówimy, że wektor losowy c=(c_1,...,c_n) ma rozkład równomierny na zbiorze S, tzn. na zbiorze „całych punktów” (n-1)-wymiarowego sympleksu L. W takiej sytuacji liczba p'(X,Y) jest interpretowana jako prawdopodobieństwo. Jest ona równa prawdopodobieństwu zdarzenia losowego polegającego na tym, że wektor losowy c=(c_1,...,c_n) znajdzie się w odległości od ustalonego wektora a(X) nie większej jak odległość między wektorami a(X) i a(Y). Im mniejsze to prawdopodobieństwo, tym mniej przypadkowa rozpatrywana przez nas bliskość wektorów a(X) i a(Y). Inaczej mówiąc, ich bliskość wskazuje na istnienie pewnej zależności między nimi. Ponadto zależność ta jest tym większa, im mniejsza wartość parametru p'(X,Y). Równomierność rozkładu wektora losowego c=(c_1,...,c_n) na sympleksie L, a dokładniej mówiąc, na zbiorze S jego „całych punktów”, może być spowodowana tym, że wektor ten odwzorowuje odległości między sąsiednimi lokalnymi maksimami funkcji pojemności „rozdziałów” kronik historycznych i innych analogicznych tekstów, opisujących zadany okres czasu (A,B). Rozpatrując wszelkie możliwe kroniki wydaje się oczywiste, że lokalne maksimum może „z równym prawdopodobieństwem” pojawiać się w dowolnym punkcie przedziału czasowego (A,B). Wcześniej było przyjęte założenie z wariantem wprowadzenia maksimów krotnych na wykresach pojemności kronik. Rozpatrzmy wszystkie takie warianty i obiczmy dla każdego z nich przypisaną mu liczbę p'(X,Y), a następnie weźmy najmniejszą z otrzymanych w ten sposób liczb. Oznaczmy tę liczbę jako p''(X,Y). To znaczy, teraz minimalizujemy parametr p'(X,Y) wszelkimi możliwymi sposobami wprowadzenia lokalnych maksimów na wykresach vol X(t) i vol Y(t). Po wykonaniu obliczeń dla parametru p''(X,Y) okazało się, że kroniki X i Y znajdują się w niepełnoprawnym położeniu. Rzecz polega na tym, że powyżej rozpatrywano ”n-wymiarową kulę” o promieniu r(X,Y) ze środkiem w punkcie a(X). Aby zlikwidować zaistniałą nierównoprawność między kronikami X i Y, zamienimy je po prostu miejscami i powtórzymy cała wyżej opisaną procedurę, przyjmując środek „n-wymiarowej kuli” w punkcie a(Y). Otrzymamy wówczas pewną liczbę, którą oznaczymy jako p''(Y,X). Zamiast „symetrycznego współczynnika” p(X,Y) weźmiemy średnią arytmetyczną z liczb p''(X,Y) i p''(Y,X), to znaczy: p''(X,Y) + p''(Y,X)
Jeśli odległość między punktem a(X) i punktem a(Y) oznaczymy przez |a(X)-a(Y)|, to wtedy zbiór K będzie stanowił przecięcie trójkąta L z trójwymiarowym kołem, którego środek znajdzie się w punkcie a(X), a jego promień będzie równy |a(X)-a(Y)|. W następnej kolejności trzeba podliczyć ilość „całych punktów”, tzn. punktów ze współrzędnymi całkowitoliczbowymi, w zbiorze K i w trójkącie L. Stosunek obu otrzymanych w ten sposób liczb będzie parametrem p'(X,Y). W konkretnych obliczeniach należy posłużyć się przybliżonym sposobem wyliczenia współczynnika p(X,Y), gdyż obliczenie liczby całych punktów w zbiorze K byłoby bardzo pracochłonne. Trudność tę można jednak obejść przechodząc od „modelu dyskretnego” do „modelu ciągłego”. Dobrze wiadomo, że jeśli (n-1)-wymiarowy zbiór K w (n-1)-wymiarowym sympleksie L jest dostatecznie duży, to liczba całych punktów w K jest równa (n-1)-wymiarowej pojemności zbioru K. Dlatego też od samego początku można podstawiać pod predefiniowany współczynnik p'(X,Y) po prostu stosunek (n-1)-wymiarowej pojemności K do (n-1)-wymiarowej pojemności L. (n-1)-wymiarowa pojemność K Przykładowo mając dwa lokalne maksima, w miejsce współczynnika p'(X,Y) podstawiamy stosunek: powierzchnia zbioru K Oczywiście przy małych wartościach B-A „współczynnik dyskretny” i „współczynnik ciągły” są różne. Jednak przy analizowaniu starych tekstów mamy do czynienia z okresami czasu B-A wynoszącymi kilkadziesiąt, a nawet kilkaset lat, a więc bez groźby popełnienia większego błędu spokojnie można posłużyć się „modelem ciągłym” p'(X,Y) do przeprowadzenia obliczenia wg formuł matematycznych. EKSPERYMENTALNE POTWIERDZENIE STATYSTYCZNEGO MODELU KORELACJI LOKALNYCH MAKSIMÓW Nota bene dla tzw. par „dynastii zależnych i niezależnych” wyliczono inne współczynniki, ale to już całkiem inna, wspomniana na wstępie, metoda. Patrz rys.15:
Oto kilka przykładów przeanalizowanych tekstów: Przykład 1 W miejsce tekstu X wzięto monografię historyczną współczesnego autora Władimira Siergiejewa "Очерки по истории Древнего Рима", tom 1-2, rok 1938, a w miejsce tekstu Y - „Dzieje Rzymu” Tytusa Liwiusza, tom 1-6, 1897-1899. Wg datowania tradycyjnej chronologii oba teksty opisują tę samą epokę historyczną, ten sam okres historii „antycznego” Rzymu, tj. lata 757-287 p.n.e. Wyraźnie widać, że główne piki wykresów są praktycznie równoległe. Okazało się, że parametr p(X,Y) w tym przypadku jest równy 2x10^-12. Jego mała wartość liczbowa świadczy o tym, że jeśli rozpatrujemy bliskość położenia pików na obu wykresach jako wydarzenie losowe, to prawdopodobieństwo to jest niezwykle niskie. Jak widać, współczesny autor W.Sergiejew dostatecznie dokładnie odtworzył w swej pracy „antyczny” oryginał. Przykład 2 Wyliczenia wykazały, iż w tym przypadku współczynnik p(X,Y) = 10^-24. Jego wartość jest bardzo mała, co potwierdza zależność obu tekstów. Przykład 3
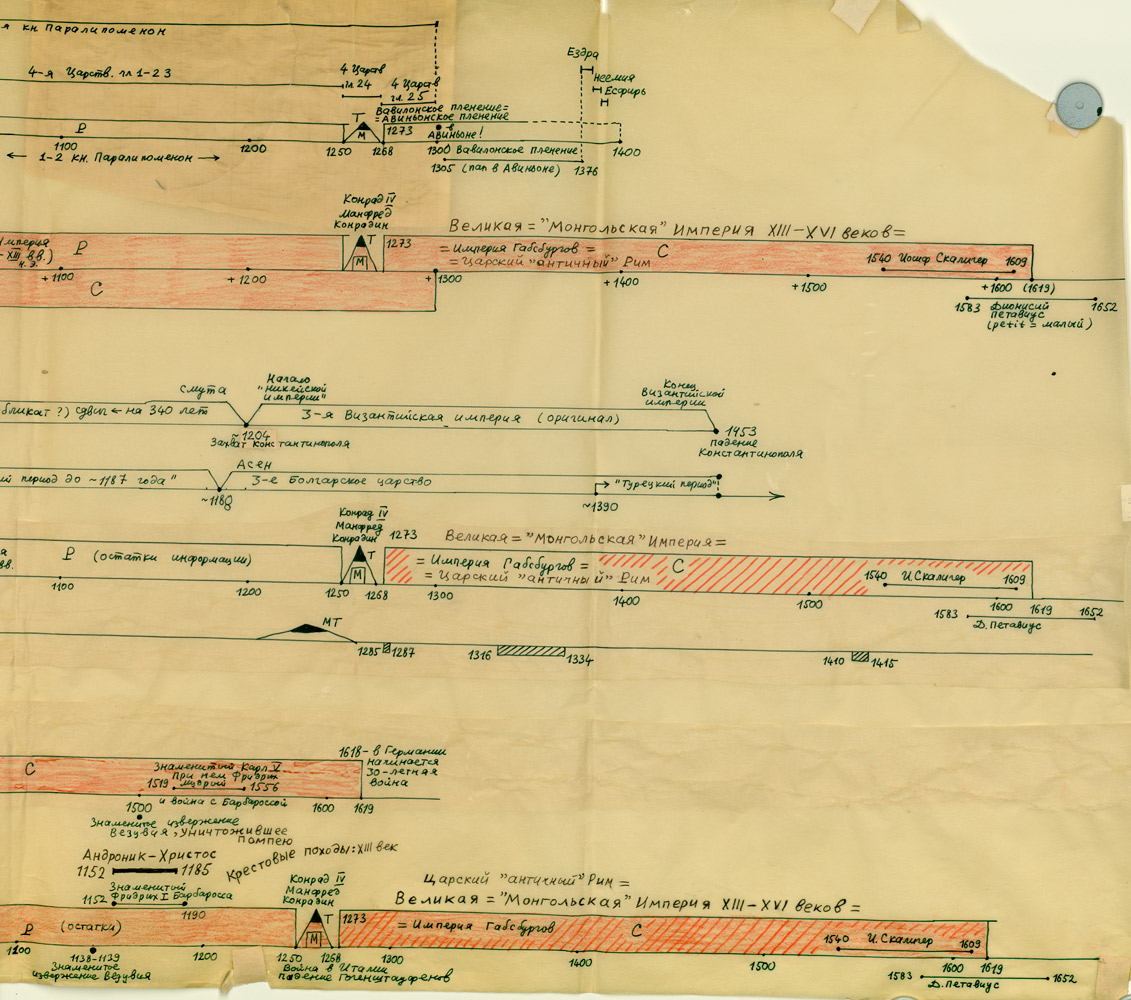
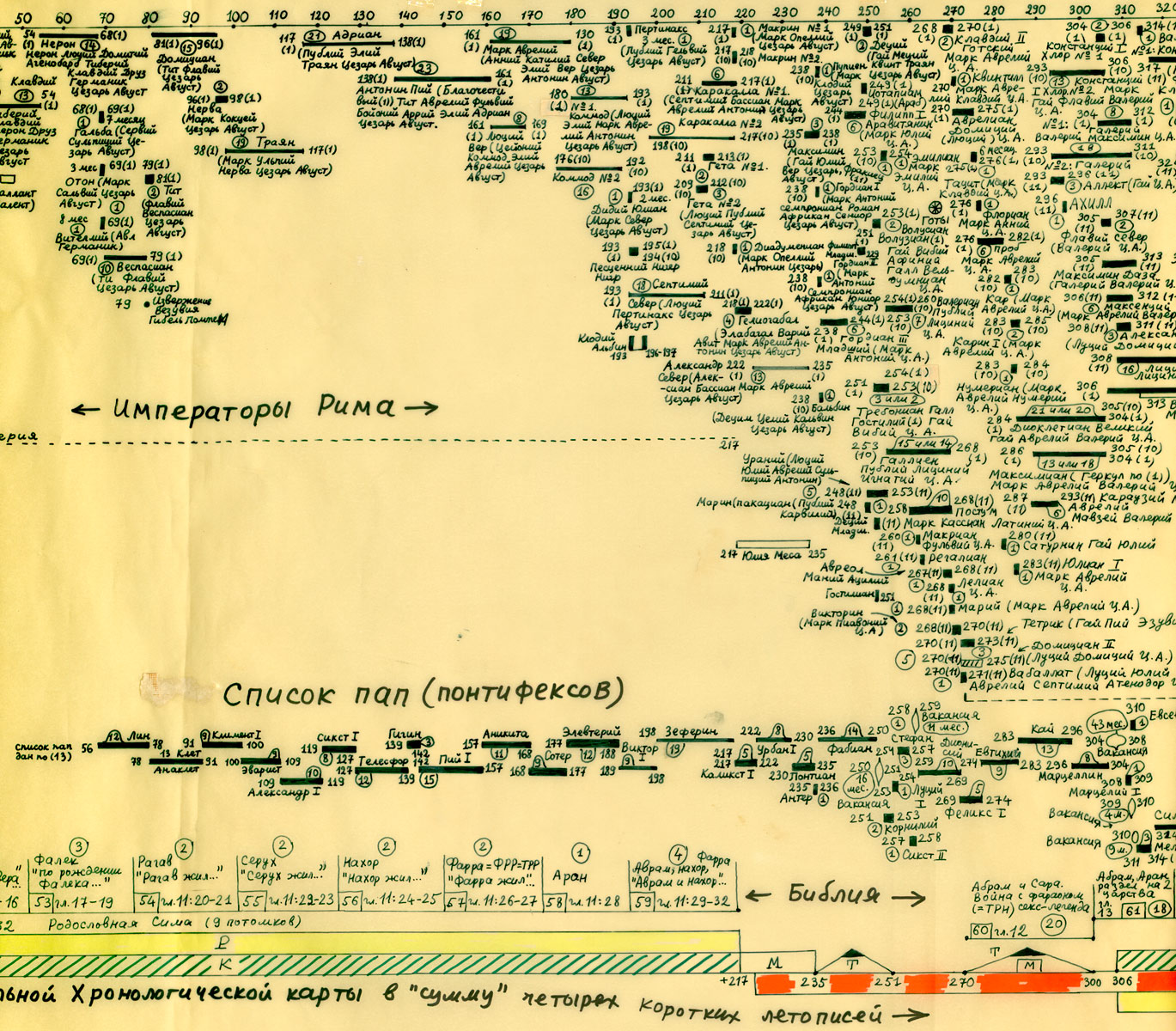
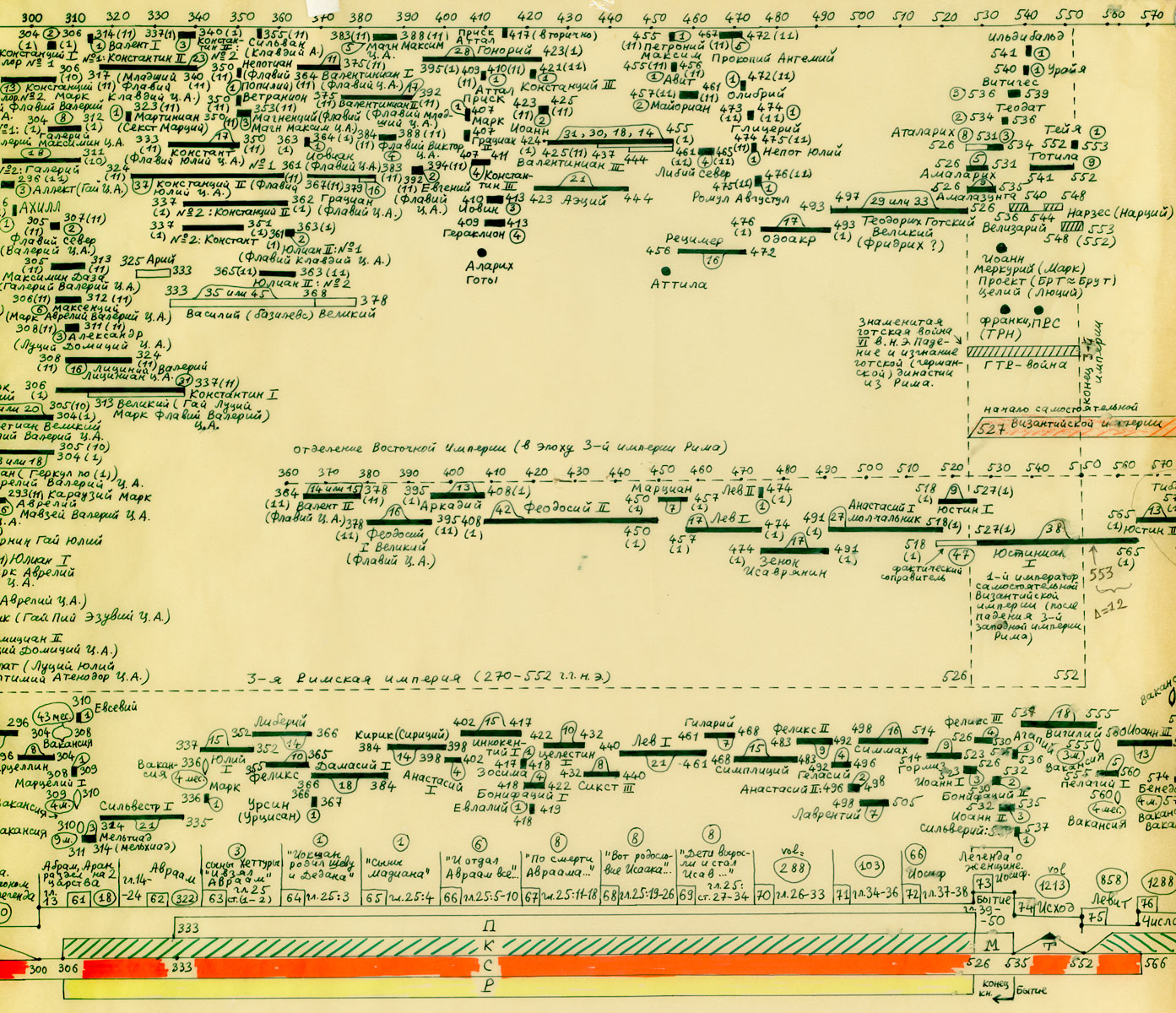
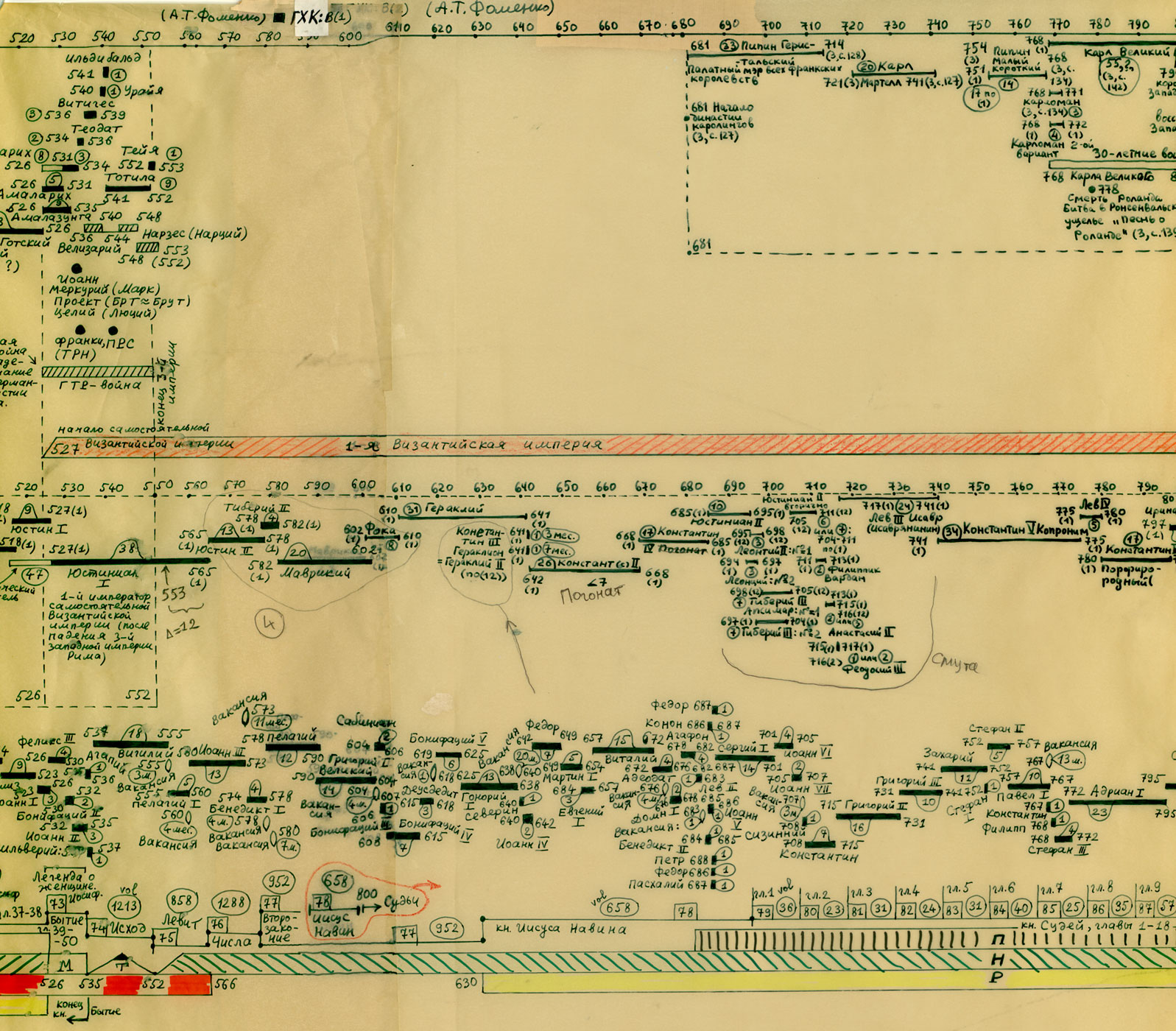
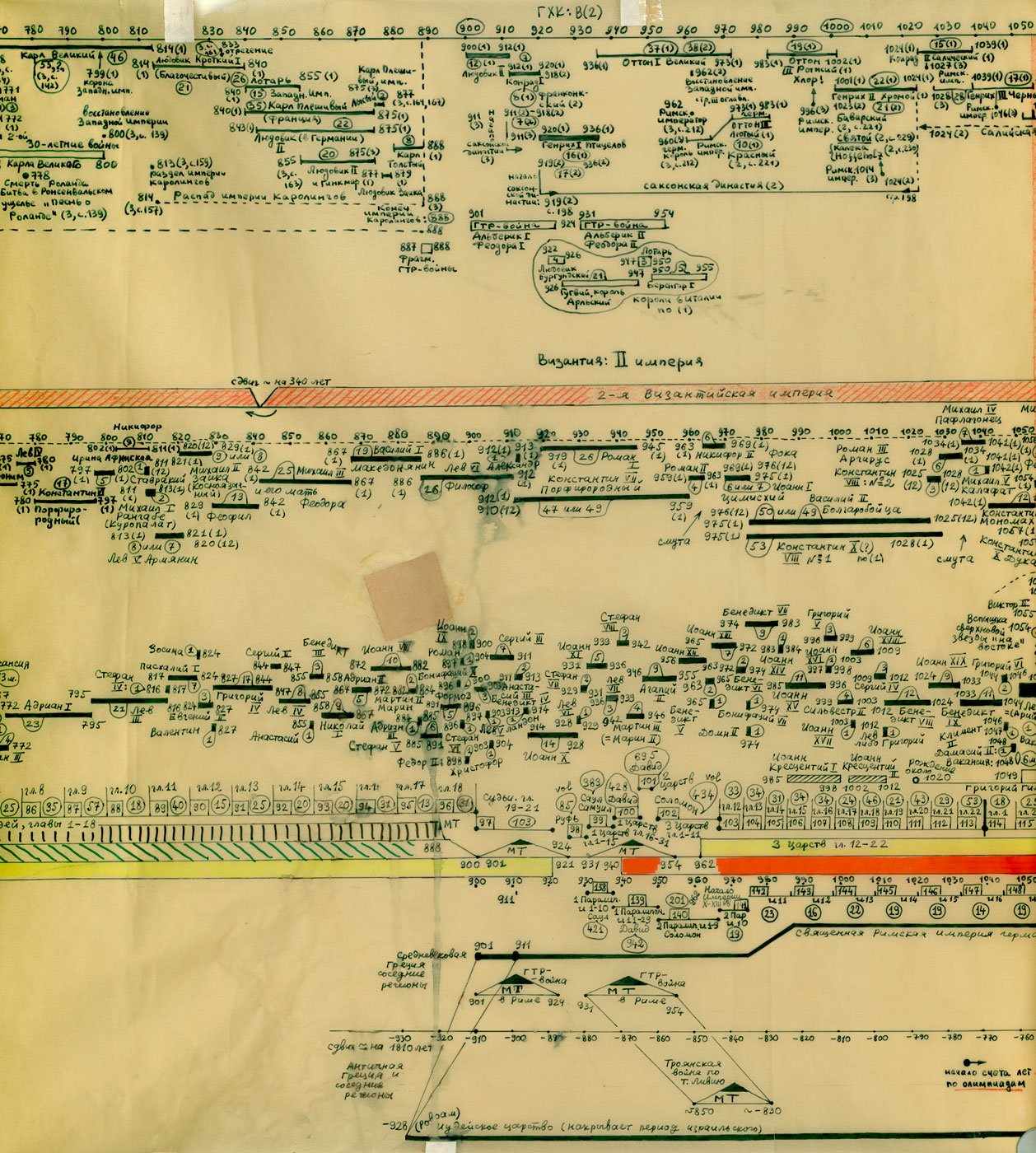
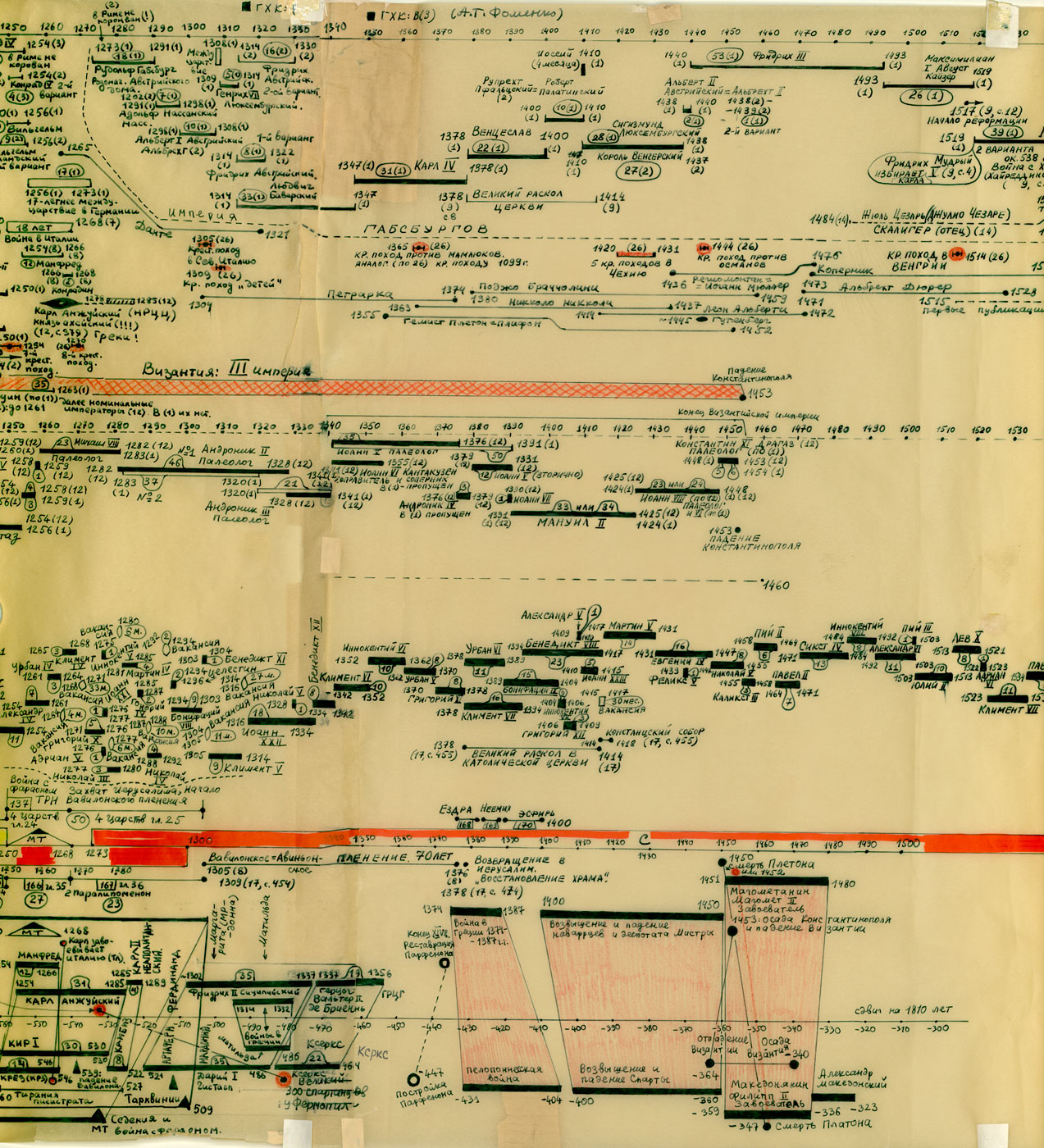
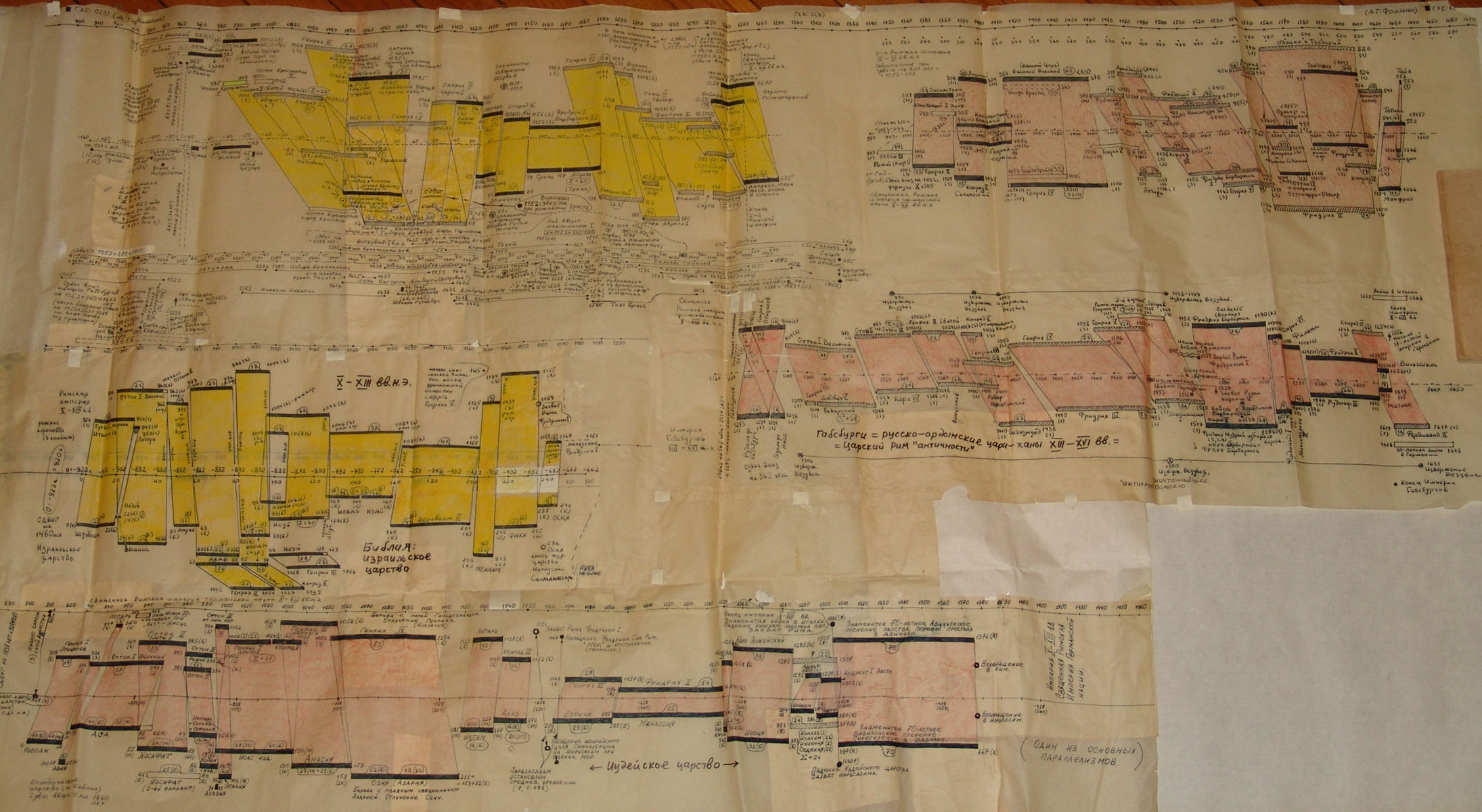
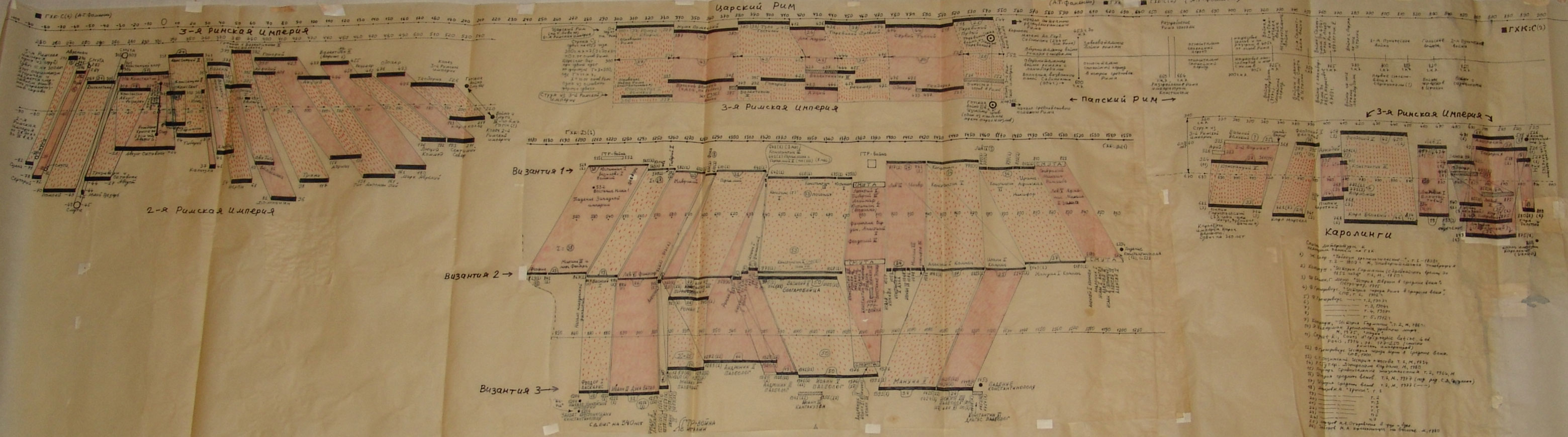
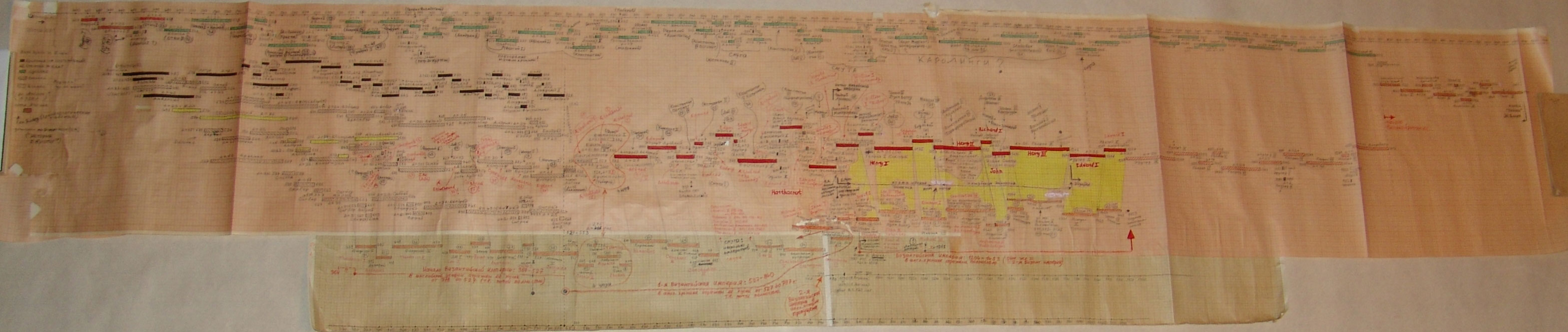
Na powyższym rys.20 zestawiono jednocześnie trzy wykresy dla Kroniki Supraślskiej, Latopisu Nikiforowskiego i Powieści Minionych Lat. Ostatnia z tych kronik jest „bogatsza”, jej wykres ma więcej lokalnych maksimów i choćby dlatego zależność tego tekstu nie wydaje się zbyt oczywista. Tym niemniej, po dokonaniu „wygładzenia”, okazuje się, że między trzema ww. kronikami istnieje ewidentna zależność. Przykład 4 Przykład 5 Podczas falsyfikacji metod statystycznych porównywano: Zwróćmy uwagę na jeszcze jeden ciekawy aspekt statystycznych metod analizy tekstów. Mianowicie, jeżeli dwa teksty historyczne są zależne, tzn. opisują ten sam „potok wydarzeń” w tym samym przedziale czasu historii tego samego państwa, to dla dowolnej pary przedstawionych wyżej ilościowych charakterystyk odpowiadające im wykresy wykazują piki w przybliżeniu w tych samych latach. Inaczej mówiąc, jeśli jakiś rok jest opisany w kronikach bardziej szczegółowo niż sąsiednie lata, to zwiększa się (lokalnie) liczba wzmianek o tym roku w obu kronikach, zwiększa się liczba imion postaci historycznych wspominanych w tym roku w obu kronikach itp. I odwrotnie, jeżeli teksty są niezależne, to żadnej korelacji między ww. ilościowymi charakterystykami po prostu nie ma i być nie może. CHRONOLOGICZNE PRZESUNIĘCIA W OBRĘBIE ROSYJSKIEJ HISTORII O 300-400 LAT Grupa ruskich kronik jakoby okresu 918-1098 n.e. wykazała w przybliżeniu te same wartości parametru alfa, co grupa znacznie późniejszych kronik 1330-1430 n.e. Ponadto stwierdzono, że prędkość przyrostu współczynnika alfa z upływem czasu jest w obu grupach tekstów praktycznie jednakowa. Swiadczy to o chronologicznym przesunięciu o 300-400 lat w stosunku do obowiązujących obecnie datowań. Z powyższego wynika, że niektóre realne wydarzenia XIV-XVI wieku zostały przesunięte na osi czasu wstecz do epoki jakoby IX-XIII wieku, gdzie umieszczono DUPLIKATY tych wydarzeń. CHRONOLOGICZNE PRZESUNIĘCIA W HISTORII EUROPY I ŚWIATA O 333, 1053 I 1778 LAT Paralelizmy w historii Europy, Bizancjum, nałożenie Biblii na historię europejską i azjatycką: Rzym (imperatorów i pontifeksów), Bizancjum, Karolingowie, Grecja: Rzym, Grecja, Habsburgowie, Biblia: Rzym, Bizancjum, Karolingowie: Anglia, Rzym i Bizancjum: Rzym i ormiańskie katolikosy: | |||
| | |||
| 8318 odsłon | średnio 4,2 (5 głosów) |
| zaloguj się lub załóż konto by oceniać i komentować | blog autora |
| Re: Matematyka pomaga lepiej zrozumieć historię | |||
| Piotr Świtecki, 2013.01.22 o 00:22 | |||
| Fascynujące. Niezwykłe! No i niestety trudne... Dziękuję za solidny tekst. Ciekawa sprawa. Co na to historycy? Fachowcy od źródeł i metod? | |||
| zaloguj się lub załóż konto aby odpowiedzieć | |||
| Re: Matematyka pomaga lepiej zrozumieć historię | |||
| w.red, 2013.01.22 o 01:03 | |||
| Ano zapewne to samo co Gomułka. Pyatając kto "przeciw" spuszczał oczy, poczym oświadczał "nie widzę" tym sposobem każde głosowanie było po jego myśli (choć to żart i "kawał" z długą brodą) | |||
| zaloguj się lub załóż konto aby odpowiedzieć | |||
| Re: Matematyka pomaga lepiej zrozumieć historię | |||
| Hanys, 2013.01.22 o 19:22 | |||
| Praktycznie całe środowisko historyków zamknęło się na tę wiedzę, z całkiem zrozumiałych powodów. Jest to na razie wiedza elitarna. Zresztą nie każdy zna i chce znać algorytmy matematyczne, macierze, rachunek prawdopodobieństwa... Lepiej udawać, że nic się nie stało. Już 30 lat minęło i cisza. W przeciwnym razie trzeba byłoby prędzej czy później pogodzić się z myślą, że cała historia ludzkości rzekomo sięgająca wielu tysięcy lat jest skonfabulowana i załgana na maksa, i przyznać oficjalnie, że np. wprawdzie "starożytny Rzym" i "starożytny Egipt" istniały, ale wcale nie były starożytne, tylko średniowieczne, że "Rzymianami" byli Moskowici, że Biblię ostatecznie zredagowano w XVI-XIX wieku itp. itd. A takie obrazoburcze i niesłychane "herezje" podważają przecież podstawy konsensusu historycznego i grożą rewolucją w umysłach ludzi. Po co to komu potrzebne? | |||
| zaloguj się lub załóż konto aby odpowiedzieć | |||
| Re: Matematyka pomaga lepiej zrozumieć historię | |||
| w.red, 2013.01.22 o 01:09 | |||
| Trafne, niemniej muszę poświęcić wiecej czasu by to "przetrawić". Swoją drogą nie myślałem, że matematyka posłuży do weryfikowania naszych dziejów w podobny sposób. | |||
| zaloguj się lub załóż konto aby odpowiedzieć | |||
| Re: Matematyka pomaga lepiej zrozumieć historię | |||
| Hanys, 2013.01.22 o 18:06 | |||
| Mocno się natrudziłem, ale chciałem pokazać ideę i podstawy tej metodyki. Rachunek prawdopodobieństwa i statystyka pomagają precyzyjnie prognozować udział wyborców w wyborach, a o tym, że równie efektywnie mogą pomóc przy analizie chronologii dziejów i starych tekstów, których sens już dawno przeredagowano i wypaczono, prawie nikt nie wie. Te metody istnieją od 30 lat i co z tego? Mój głos też tu nic nie da, mogę sobie tylko trochę poszczekać, a karawana i tak pojedzie dalej. Podobnie sprawy wyglądają np. z budową piramid. Pisze się setki książek o starożytnym Egipcie, a już od 30 lat wiadomo, jak piramidy zbudowano, i znane są w miarę prawdziwe datowania astronomiczne, które całkowicie zadają kłam powszechnie obowiązujacej wersji, no i co z tego? Krytyków i kontestatorów bierze się na przeczekanie, w końcu kiedyś umrą, a ich prace pójdą na przemiał. | |||
| zaloguj się lub załóż konto aby odpowiedzieć | |||
| Re: Matematyka pomaga lepiej zrozumieć historię | |||
| w.red, 2013.01.23 o 23:28 | |||
| Co z tego pytasz? Może tyle że zostanie coś w ludzkich umysłach by po latach upomnieć się o prawdę. Nie da się wiecznie żyć w kłamstwie i niewiedzy. pozdrawiam | |||
| zaloguj się lub załóż konto aby odpowiedzieć | |||
| Re: Matematyka pomaga lepiej zrozumieć historię | |||
| Pak4, 2014.09.01 o 13:19 | |||
| > "Rachunek prawdopodobieństwa i statystyka pomagają precyzyjnie prognozować udział wyborców w wyborach" Jeśli mamy odpowiednio liczną próbkę. Przeciwko Fomience i innym, jest za dużo argumentów, by traktować ich serio. | |||
| zaloguj się lub załóż konto aby odpowiedzieć | |||
| Re: Matematyka pomaga lepiej zrozumieć historię | |||
| Hanys, 2014.09.01 o 17:38 | |||
| Przeczytałe(a)ś którąkolwiek z ich najwcześniejszych prac (np. tę: МЕТОДЫ СТАТИСТИЧЕСКОГО АНАЛИЗА ИСТОРИЧЕСКИХ ТЕКСТОВ, Jeśli żadnej, to z kolei ja nie mogę Ciebie traktować serio. | |||
| zaloguj się lub załóż konto aby odpowiedzieć | |||
| Re: Matematyka pomaga lepiej zrozumieć historię | |||
| Marek Stefan Szmidt, 2014.09.01 o 14:06 | |||
| Szanowny Autorze, oceniłem na 5 punktów za zgodność z prądami w filozofii lat 1680-1715 pozdrawiam serdecznie MStS | |||
| zaloguj się lub załóż konto aby odpowiedzieć | |||
| Re: Matematyka pomaga lepiej zrozumieć historię | |||
| Hanys, 2014.09.01 o 17:47 | |||
| Szanowny Konserwatorze Wstrzymam się z komentarzem do Pańskiego zgryźliwego komentarza. Ja ten artykuł napisałem w styczniu ubiegłego roku. Dlaczego Pan reaguje nań dopiero teraz? Zaczynam poważnie wątpić, czy Pańska reakcja nadąża za chronologią najnowszych wydarzeń 2013/2014 roku. | |||
| zaloguj się lub załóż konto aby odpowiedzieć | |||
| Re: Matematyka pomaga lepiej zrozumieć historię | |||
| Marek Stefan Szmidt, 2014.09.01 o 21:43 | |||
| Szanowny Panie, dopiero dzisiej wpadł Mi w oko, a poza tym Mój komentarz wcale nie jest zgryźliwy pozdrawiam Pana serdecznie MStS | |||
| zaloguj się lub załóż konto aby odpowiedzieć | |||
| Re: Matematyka pomaga lepiej zrozumieć historię | |||
| Hanys, 2014.09.01 o 22:24 | |||
| No to zgódźmy się, że był uszczypliwy, a nie zgryźliwy, dobrze? Także Pana pozdrawiam i życzę dużo zdrowia | |||
| zaloguj się lub załóż konto aby odpowiedzieć | |||
| Re: Matematyka pomaga lepiej zrozumieć historię | |||
| Marek Stefan Szmidt, 2014.09.02 o 11:17 | |||
| Szanowny Oponencie, nie był nawet uszczypliwy, lecz w 100% odpowiada faktom zapisanym przez uczestników dyskusji z lat 1680-1715, co można potwierdzić empirycznie, po prostu czytając te pozycje. :-) serdeczne pozdrowienia MStS | |||
| zaloguj się lub załóż konto aby odpowiedzieć | |||
| Re: Matematyka pomaga lepiej zrozumieć historię | |||
| Hanys, 2014.09.02 o 17:21 | |||
| Chętnie bym poznał te pozycje z XVII i XVIII wieku, które Pan miał na myśli. Do tej pory byłem przekonany, że wszelka beletrystyka historyczna powstała dopiero w XIX wieku, pod bacznym okiem wszechobecnego cenzora. Chyba nie twierdzi Pan, że ze specjalnej XVII-wiecznej literatury "filozoficznej", którą tylko Pan zna, będę mógł się dowiedzieć na przykład, że rozkwit Cesarstwa Rzymskiego przypadł na XVIII wiek, zaś Jerozolima powstała w XIX wieku, a Moskwa w XX wieku? Pozdrawiam | |||
| zaloguj się lub załóż konto aby odpowiedzieć | |||
| Re: Matematyka pomaga lepiej zrozumieć historię | |||
| Marek Stefan Szmidt, 2014.09.02 o 17:27 | |||
| Szanowny Panie, pełen spis i przegląd najważniejszych pozycji w tym temacie znajdzie Pan w książce Paula Hazard (z roku 1935, czyli nie tylko z wieku XIX-go, a nawet XX-go) "Kryzys świadomości europejskiej 1680-1715" wydanie polskie PIW, 1974 - dostępnej m.innymi na Allegro. miłej lektury życzy MStS | |||
| zaloguj się lub załóż konto aby odpowiedzieć | |||
| © Polacy.eu.org 2010-2024 | Subskrypcje: | ↑ do góry ↑ |


 rys.1
rys.1 rys.2
rys.2 rys.3
rys.3 rys.4
rys.4 rys.5
rys.5 rys.6
rys.6 rys.7
rys.7 rys.8
rys.8 rys.9
rys.9 rys.10
rys.10 rys.11
rys.11 rys.12
rys.12
 rys.14
rys.14 rys.15
rys.15  rys.16
rys.16 rys.17
rys.17 rys.18
rys.18 rys.19
rys.19 rys.20
rys.20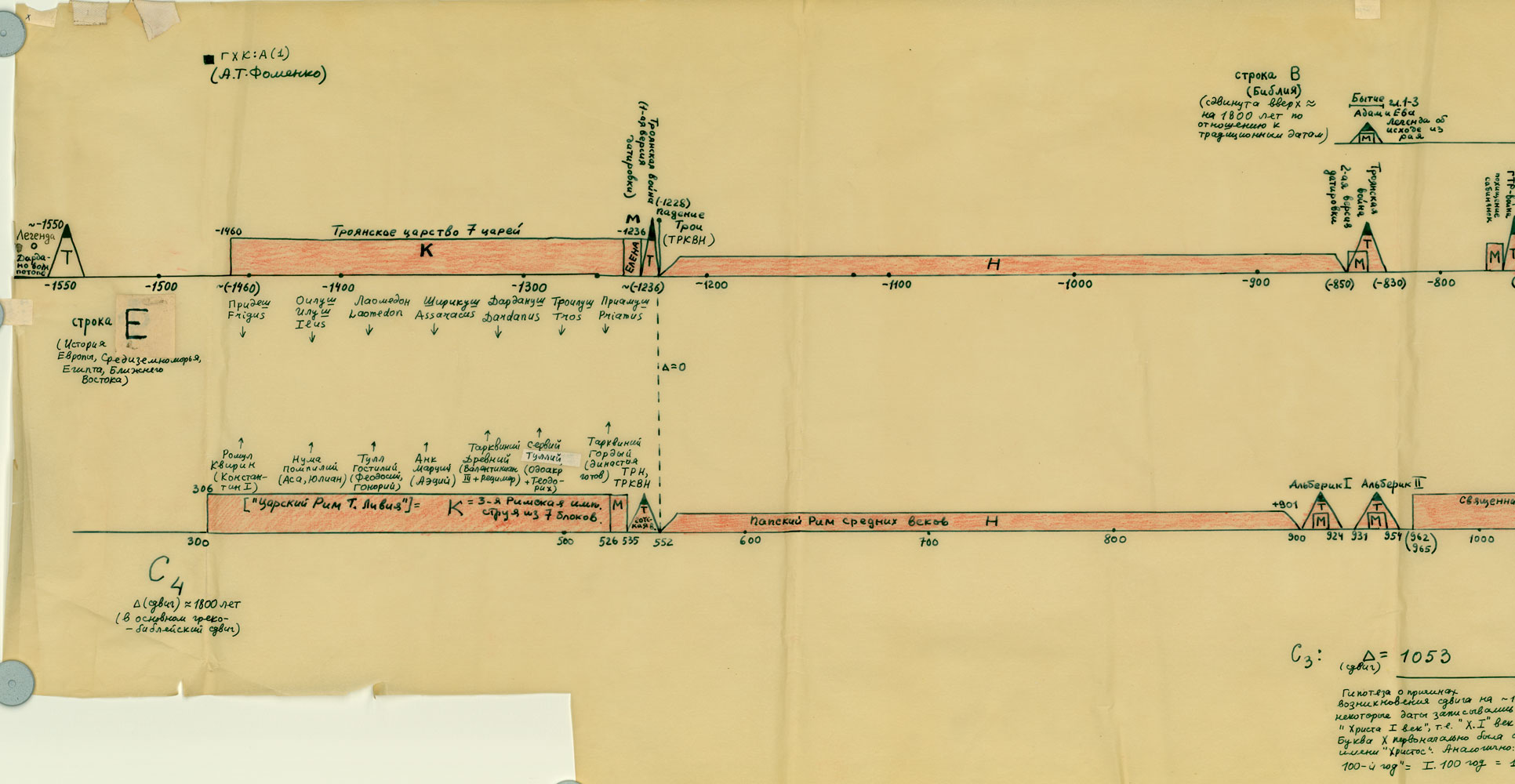{kind=link}
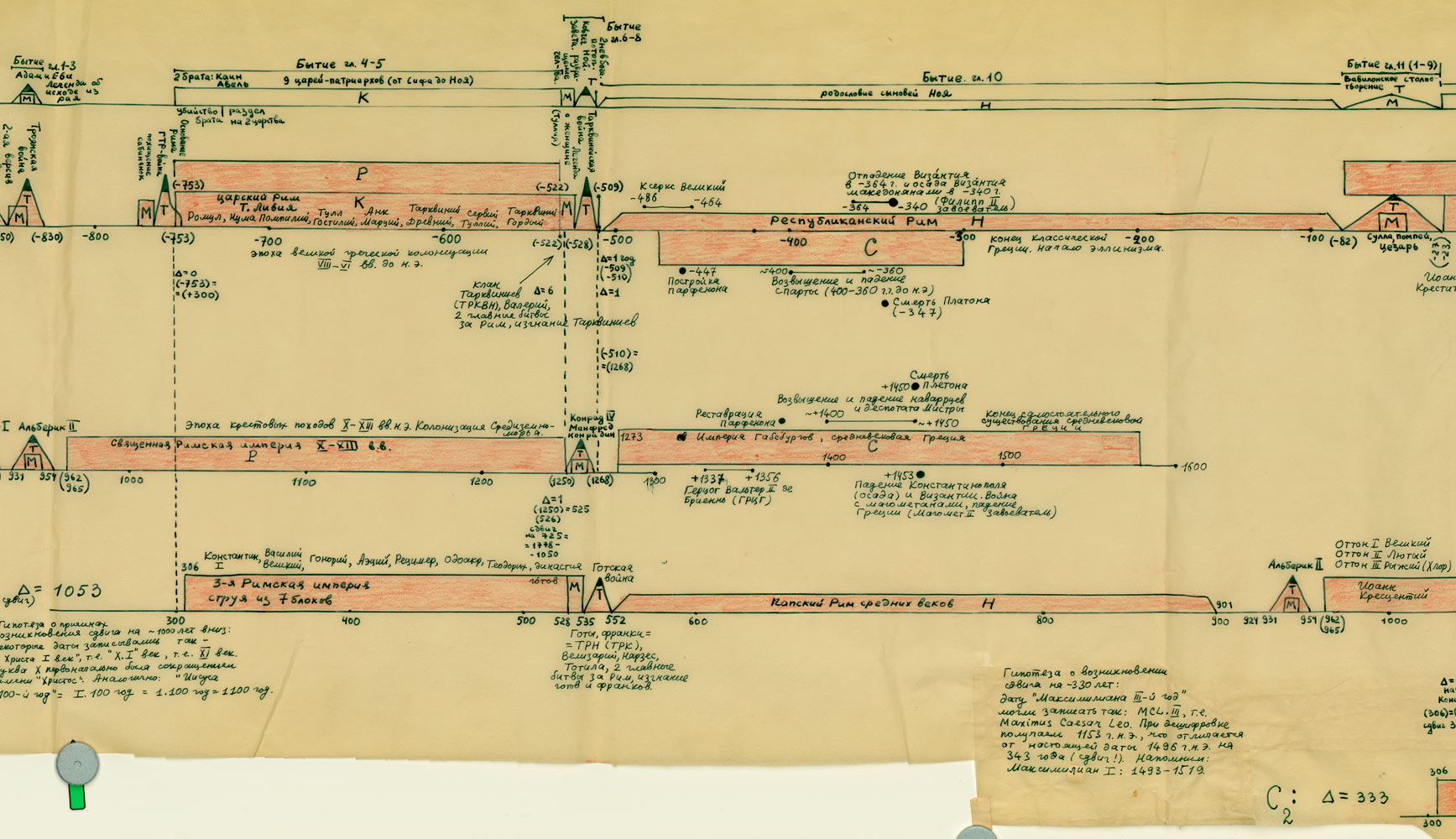{kind=link}
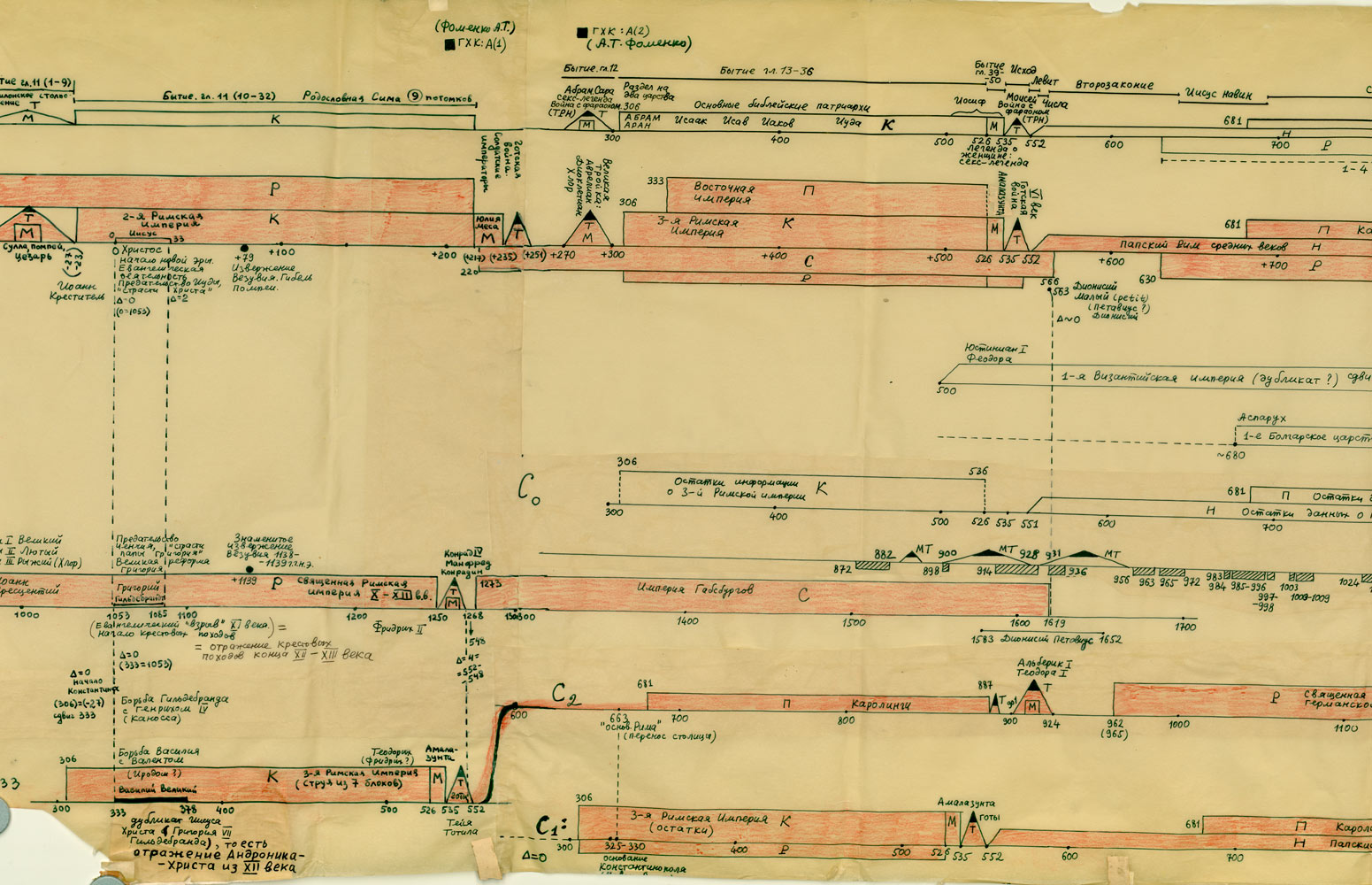{kind=link}
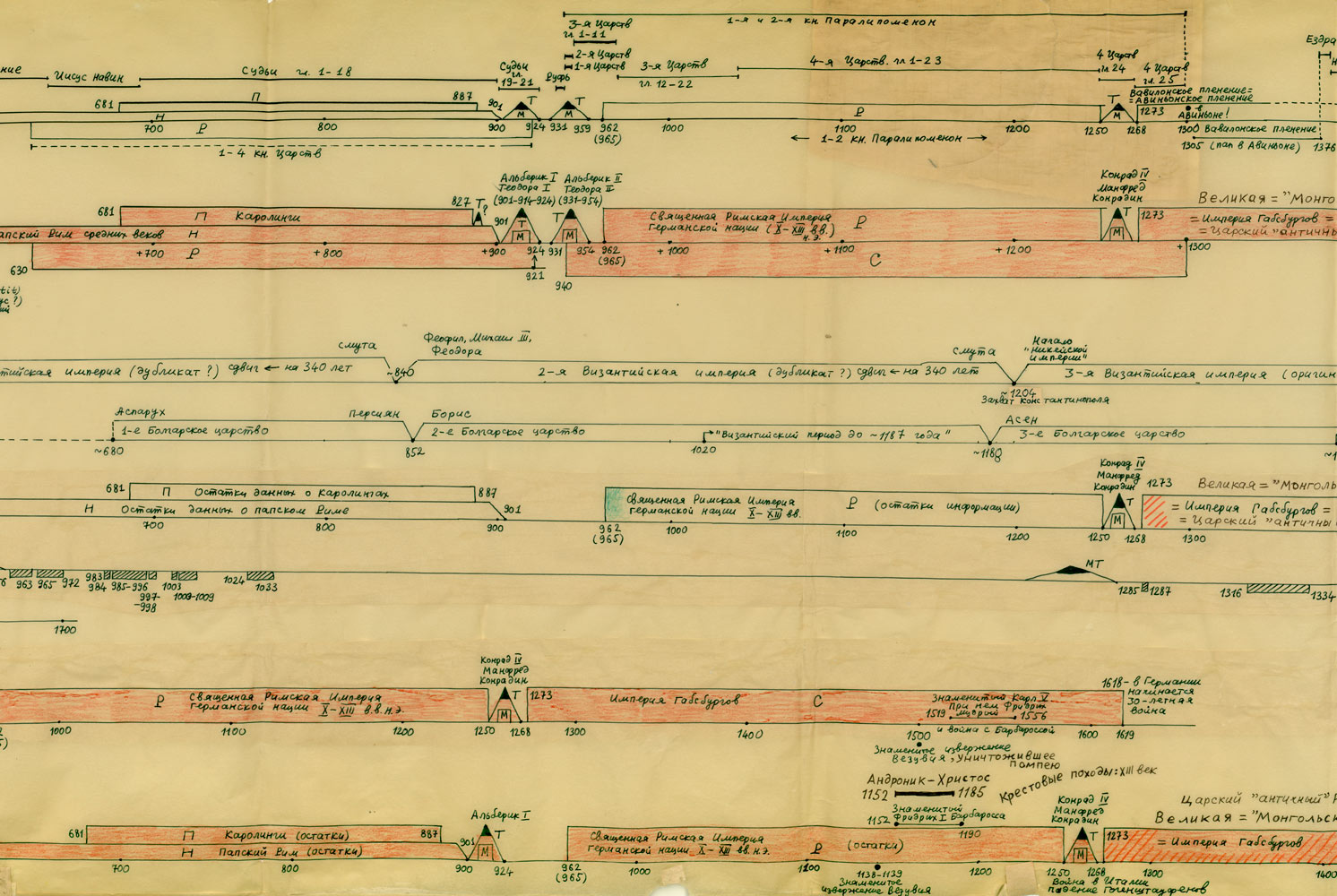{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}